





引入
Diffusion Model是如何运作的
- 就像把石头雕刻成雕塑,DiffusionModel是将一张充满噪声(noise)的图片不断Denoise最后生成图片的过程
_01.png)
- Denoise模组内部实际做的事情
在遇到一个图片的Denoise过程的时候,先计算出噪声的严重程度,然后推断出需要消去的噪声(这个在训练模型的时候的step),最后一步步生成图片
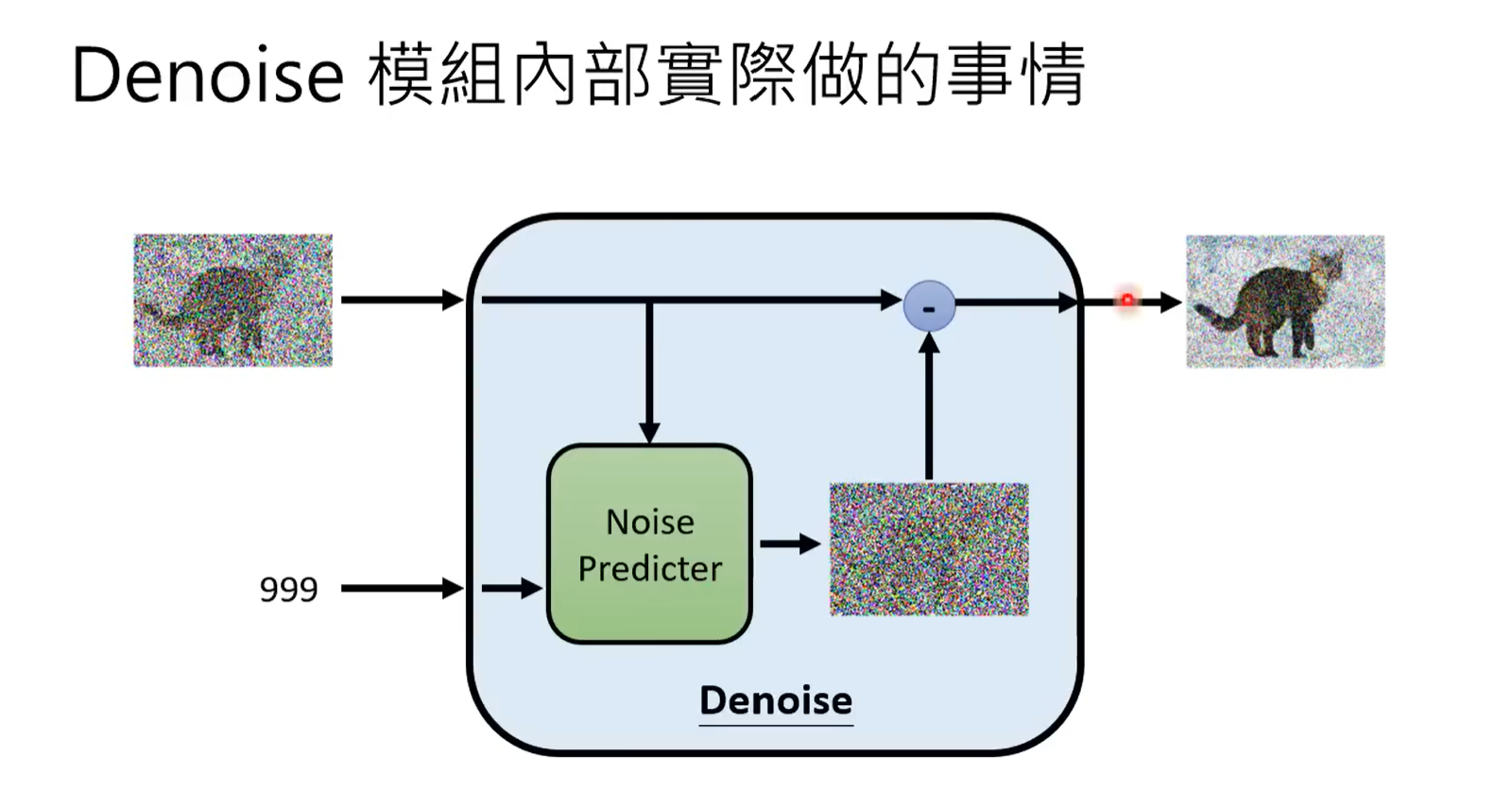
- 类似于一种自我监督的训练方式
* 先加噪声训练,然后遇到一个有噪声的图片,用这个模型就可以去噪
* 要使文字可以影响生成的图片,只要在每次训练的时候记录即可
Stable Diffusion
文字生成的一个个向量,通过消去GenerationModel产生的一个矩阵,生成一个“一个中间产物”(图片的压缩版本),即产生最后的Decoder,还原成原来的图片。例如:Stable Diffusion、DALL-E series、Imagen
- Encode越来越大(好的文字的Encoder),图片的生成结果越好(对文字的理解更好)
- 增大DiffusionModel对生成图像的效果是有限的
Frechet Inception Distance(FID)
- 一种判断图像生成效果的参数:假设真正的图像和生成的图像满足高斯分布,计算它们之间的Frechet Distance.
Smaller is better
- 缺点:需要大量的样本(sample)
- 注解:各个图片(一张图片是一个高维度向量),任取一个维度来统计分析,发现经常是高斯分布
Contrastive Language-Image Pre-Training(CLIP)
一个对比文字和图像匹配度的模型
Encoder和Decoder
- Encoder不需要文字当作输入,而是向量形式就可以训练
- 中间产物为[Latent Representation](?隐表示)
- 先Encoder为Latent Representation再训练模型
- 生成图像使先一步步给Latent Representation Denoise,最后丢给Decoder就可以生图了。
- Encoder是文字到压缩图片,Decoder是压缩图片到高清图片
Diffusion Model背后的数学原理
VAE vs. Diffusion Model
_02.png)
Training
- x0:sample clean image
- 均匀分布 Uniform ( { 1 , … , T } ) :Uniform({1,…,T}) 表示 t 可以取自集合{1,2,…,T} 中的任何一个值
- e:sample noise
- 加权求和:t越大,噪声加的越凶狠,最终得到Noisy image
- 将sample e和计算出来的Noise predictor作差
实际上是给予一个权值直接添加noise,得到noise,训练和生成都是一样的
Sampling
- xT : sample a noise
- 循环生成z(sample a noise)